Documentation
This guide explains how Tracking Assistant is used in real operations, step by step. It is structured to help teams move from setup to governed execution without guesswork.
The content below follows the same practical loop the app supports: define, connect, observe, validate, promote, and document evidence.
Start here
Tracking Assistant is a governance layer for digital tracking operations. It helps teams keep tracking definitions, runtime behavior, and validation outcomes aligned over time.
The app is organized around project tabs that match delivery work: Specs, Assets, Traces, Monitoring, and Protocols.
- Use Specs to define events and parameters.
- Use Assets to scope and activate tracking per runtime target.
- Use Traces for controlled debugging and test runs.
- Use Monitoring for continuous quality visibility.
- Use Protocols to produce auditable validation artefacts.
The product model is intentionally explicit. Most day-to-day work relies on a small set of objects.
- Specification: a versionable contract for allowed tracking behavior.
- Section: a structured part of a specification (text, image, or event grouping).
- Event: a named tracking event with linked parameter expectations.
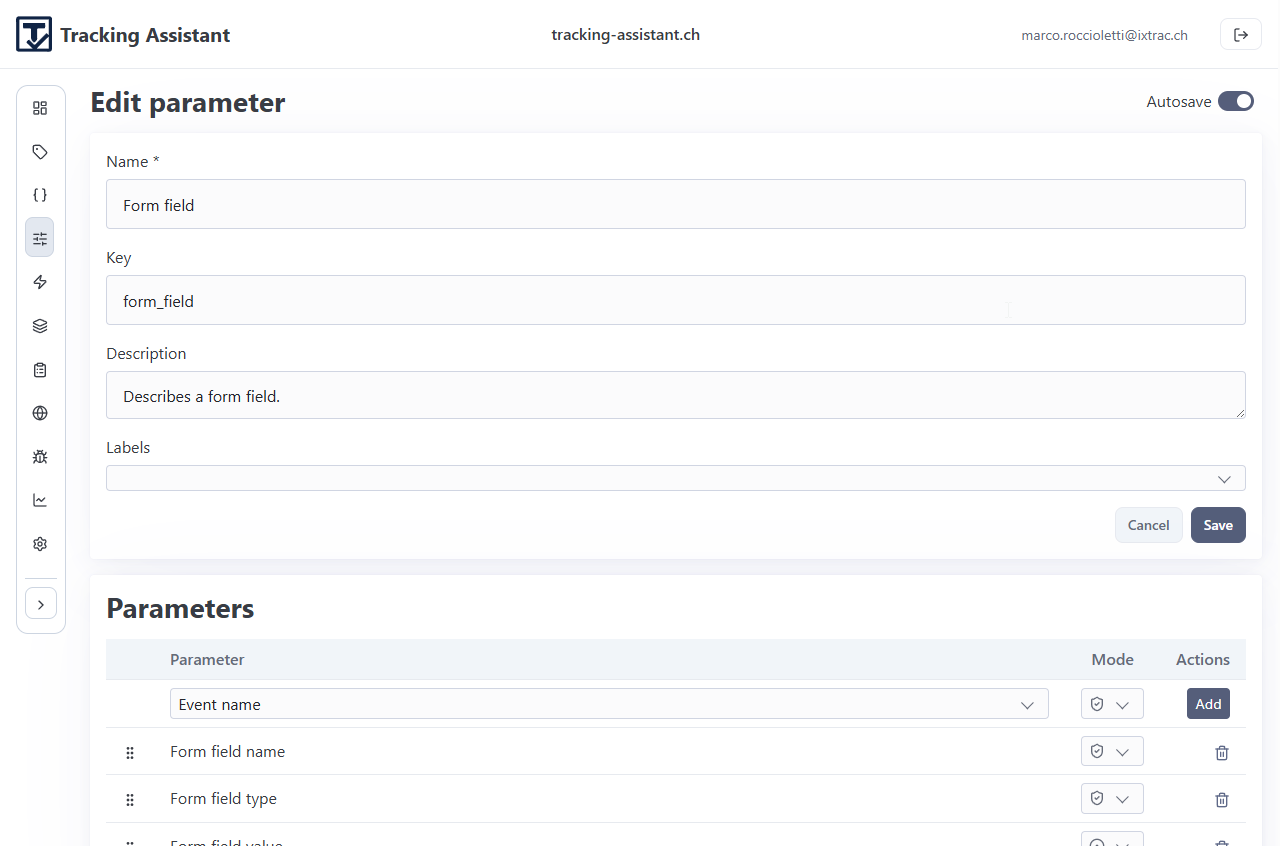
- Parameter: a tracked key with kind, format, and mode constraints.
- Asset: the concrete runtime scope where tracking executes.
- Trace: a recorded debugging session for event-level inspection.
- Monitoring bucket: aggregated runtime quality signal over time windows.
- Protocol: a test record produced from observed trace events.
Start by creating a project and defining basic shared vocabulary.
What to configure first
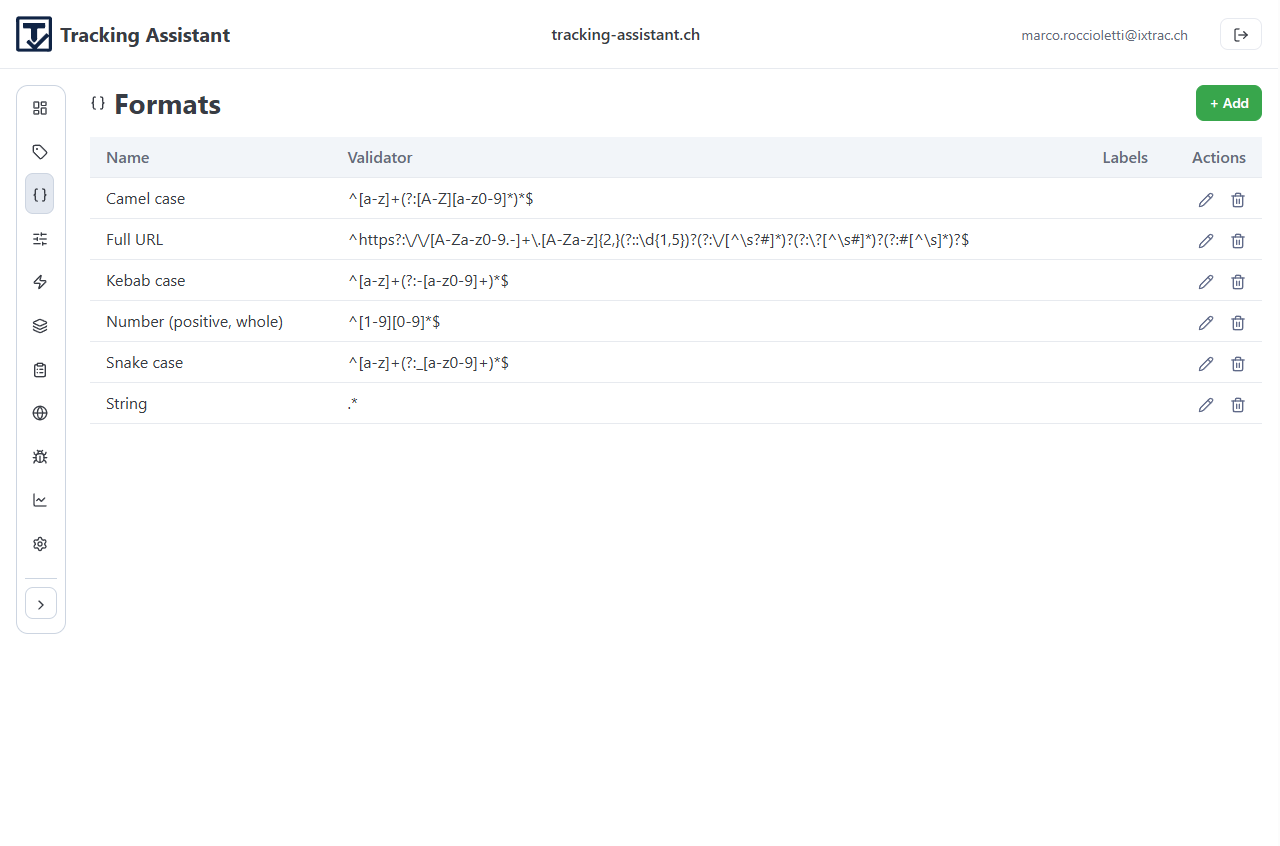
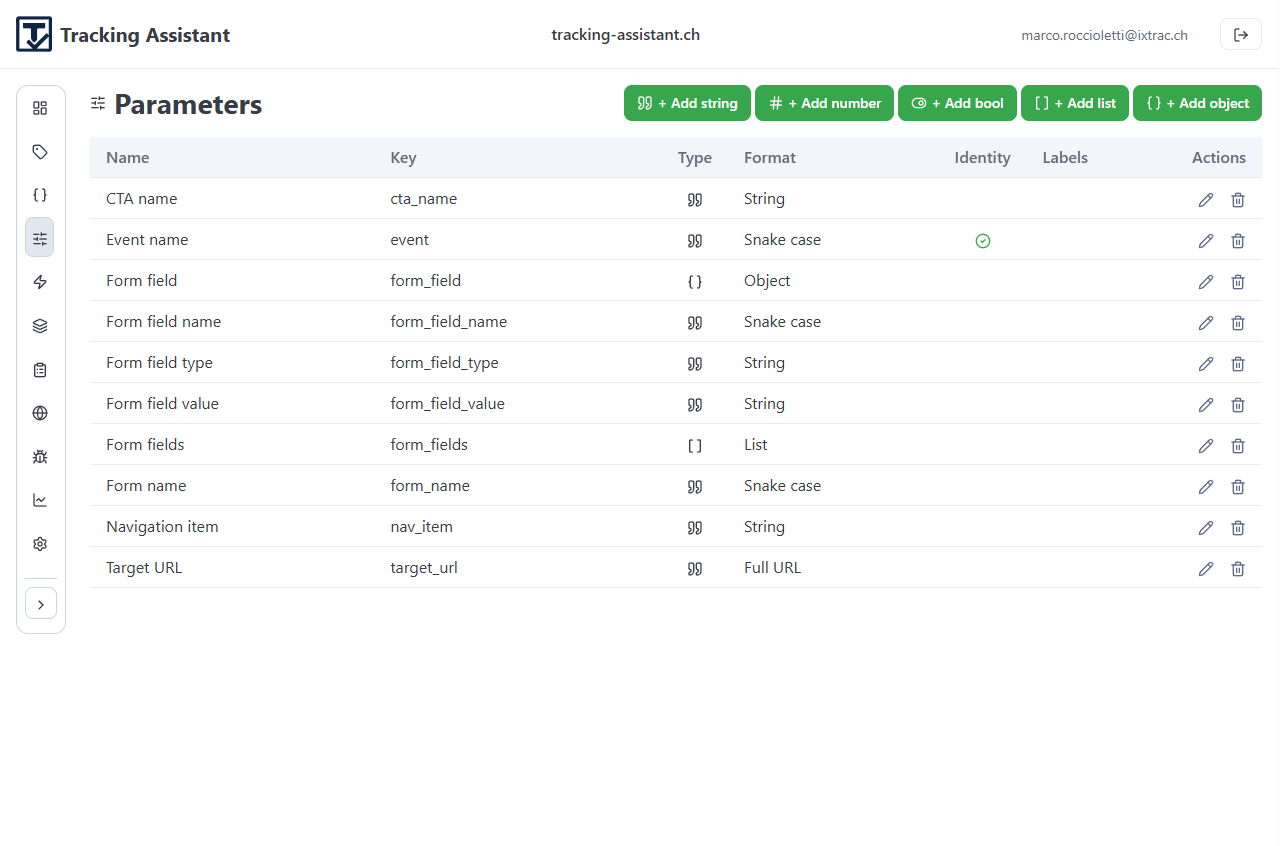
- Labels: optional taxonomy tags used across events, parameters, formats, and specs.
- Formats: reusable validators (for example regex-based constraints).
- Parameters: reusable parameter definitions with kind and optional format.
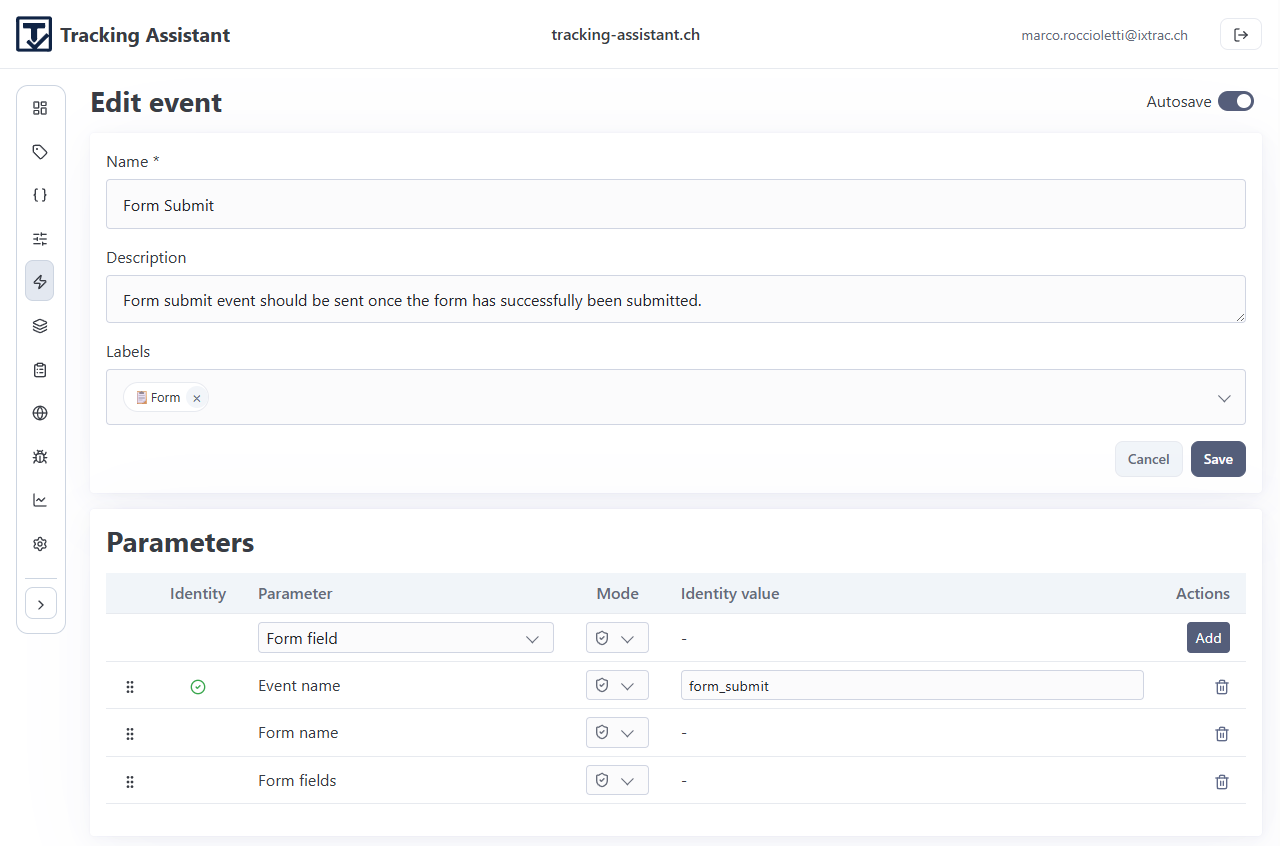
- Events: canonical event names that will later be placed into sections/specs.
This first pass should stay lightweight. The goal is to establish reusable building blocks, not model every edge case up front.
Example screens
Use the Specs tab to turn tracking intent into an explicit structure.
Typical workflow
- Create a specification.
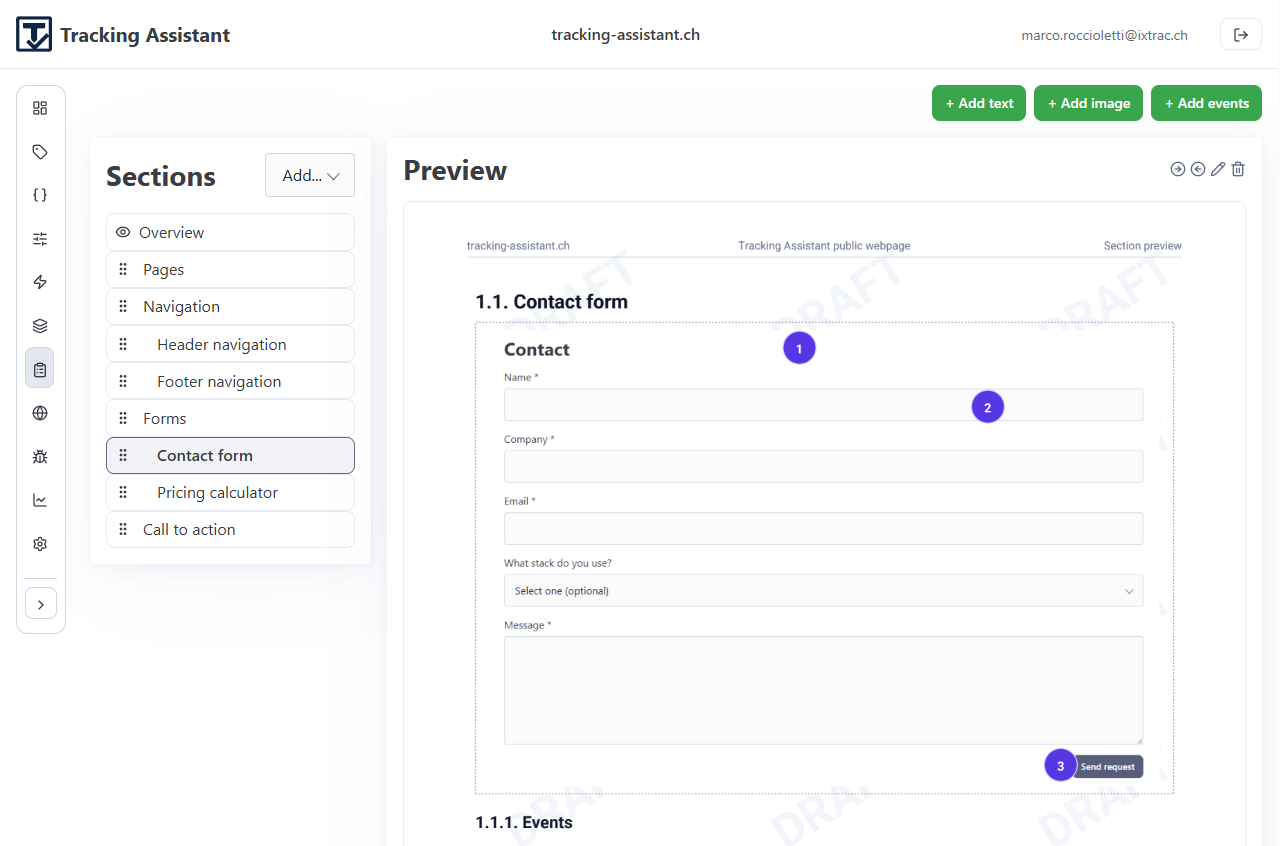
- Add existing sections or create new sections directly from spec management.
- For event sections, link events and define parameter modes (mandatory, optional, forbidden).
- Reorder and indent sections to keep large specs readable.
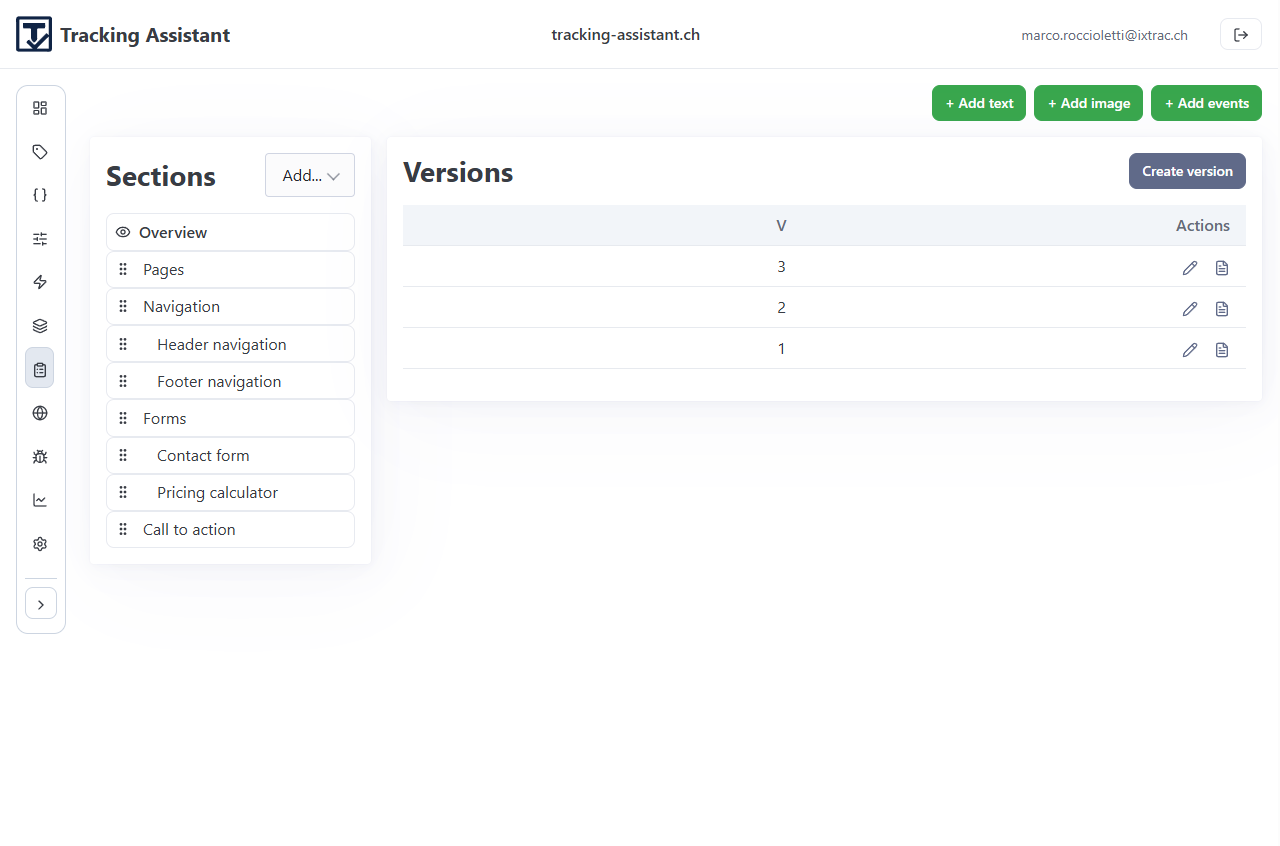
- Create a spec version once a milestone is stable.
Version snapshots are important operational checkpoints. They let teams reproduce what was expected at a given point in time and generate stable PDFs.
Open example specification PDF (v3)
Example screens
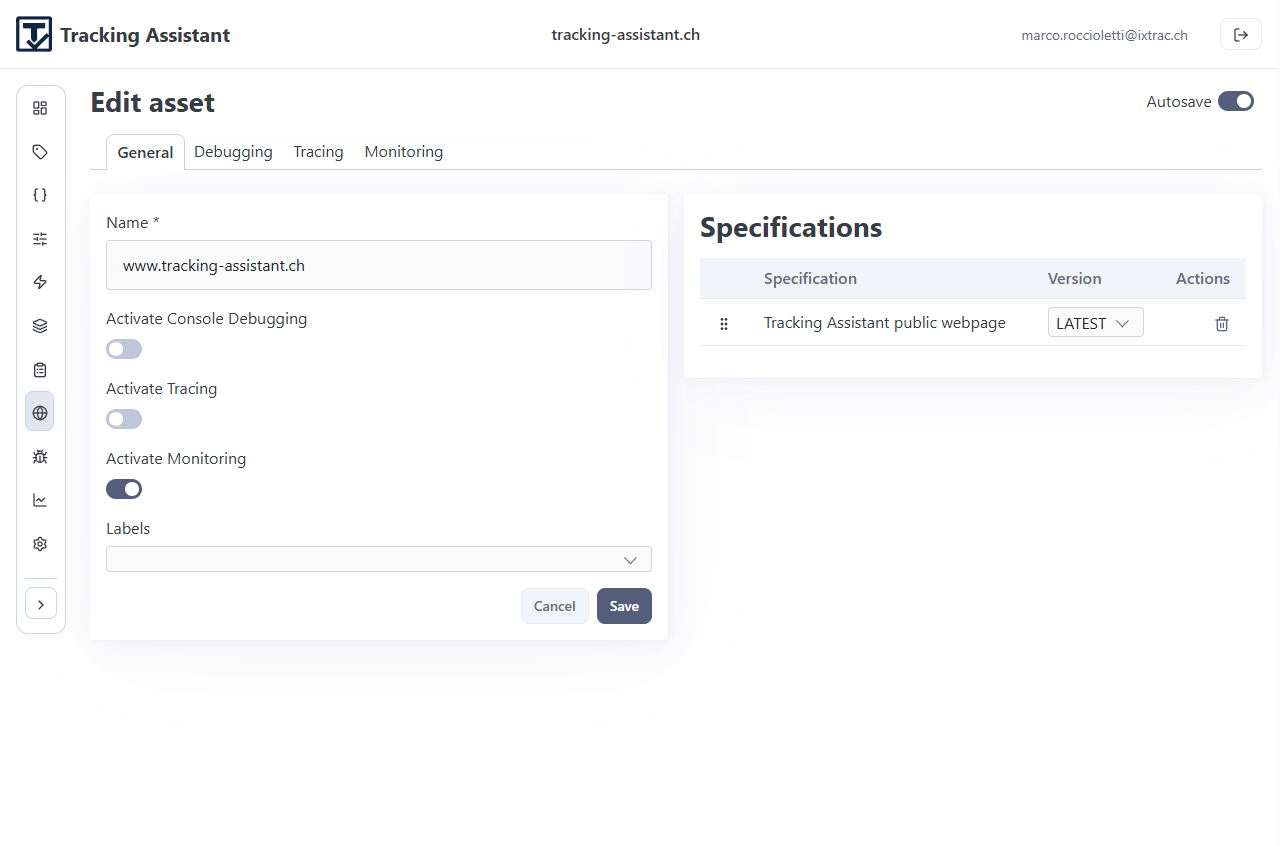
Assets connect specifications to real runtime scopes.
What needs to be set on each asset
- Name and ownership context.
- Trace start URL for debugger flows.
- Activation toggles for debugging, tracing, and monitoring.
- Monitoring retention setting.
- Linked specifications, ordered by relevance.
Roll out incrementally: one production-critical asset first, then expand.
Example screens
Use Traces when validating implementation behavior during development or release checks.
How teams use traces
- Create a new trace for an asset.
- Start polling and reproduce the relevant user flow.
- Inspect captured events and parameter-level validation status.
- Open event detail views to identify unknown events, missing parameters, and format errors.
- Select representative events and create a protocol draft.
Tracing should be used to shorten feedback loops before issues reach long-term monitoring.
Example screens
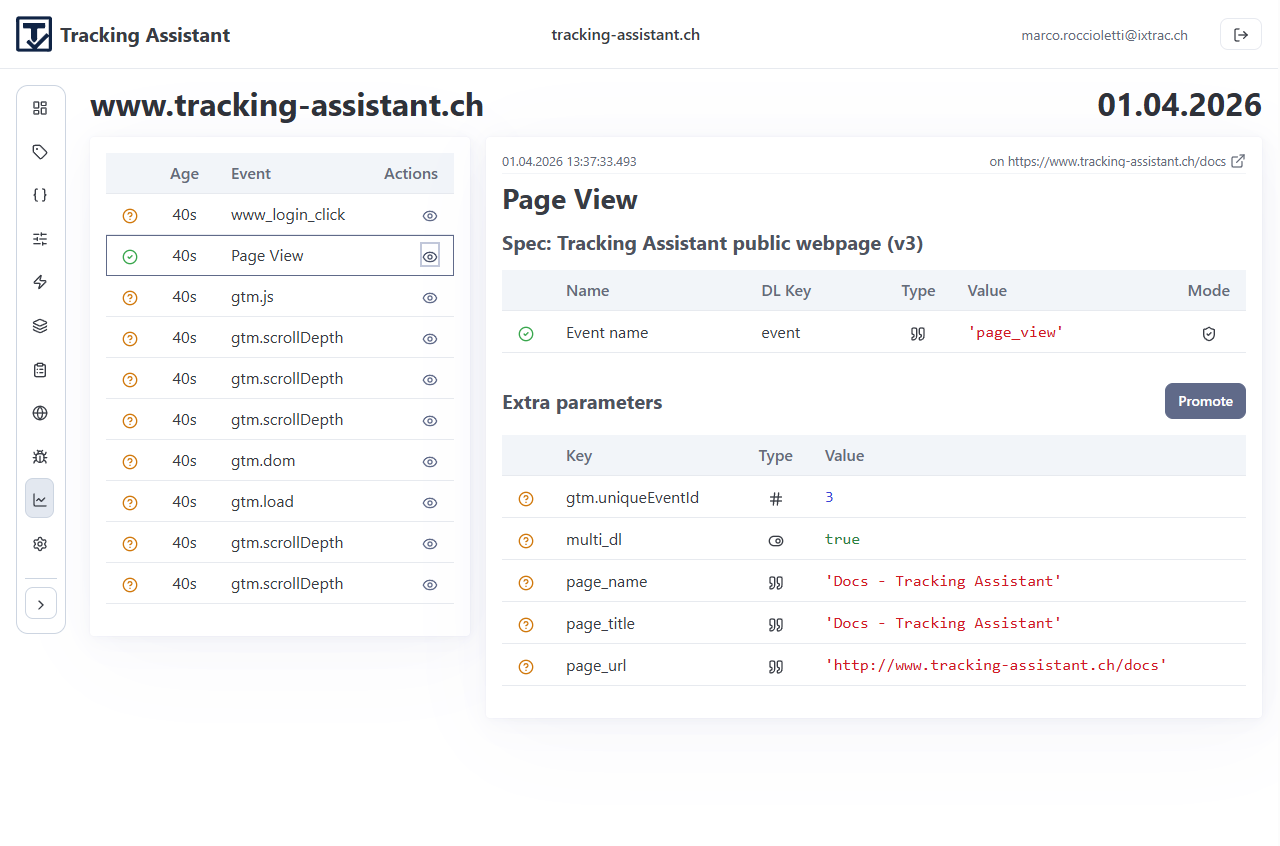
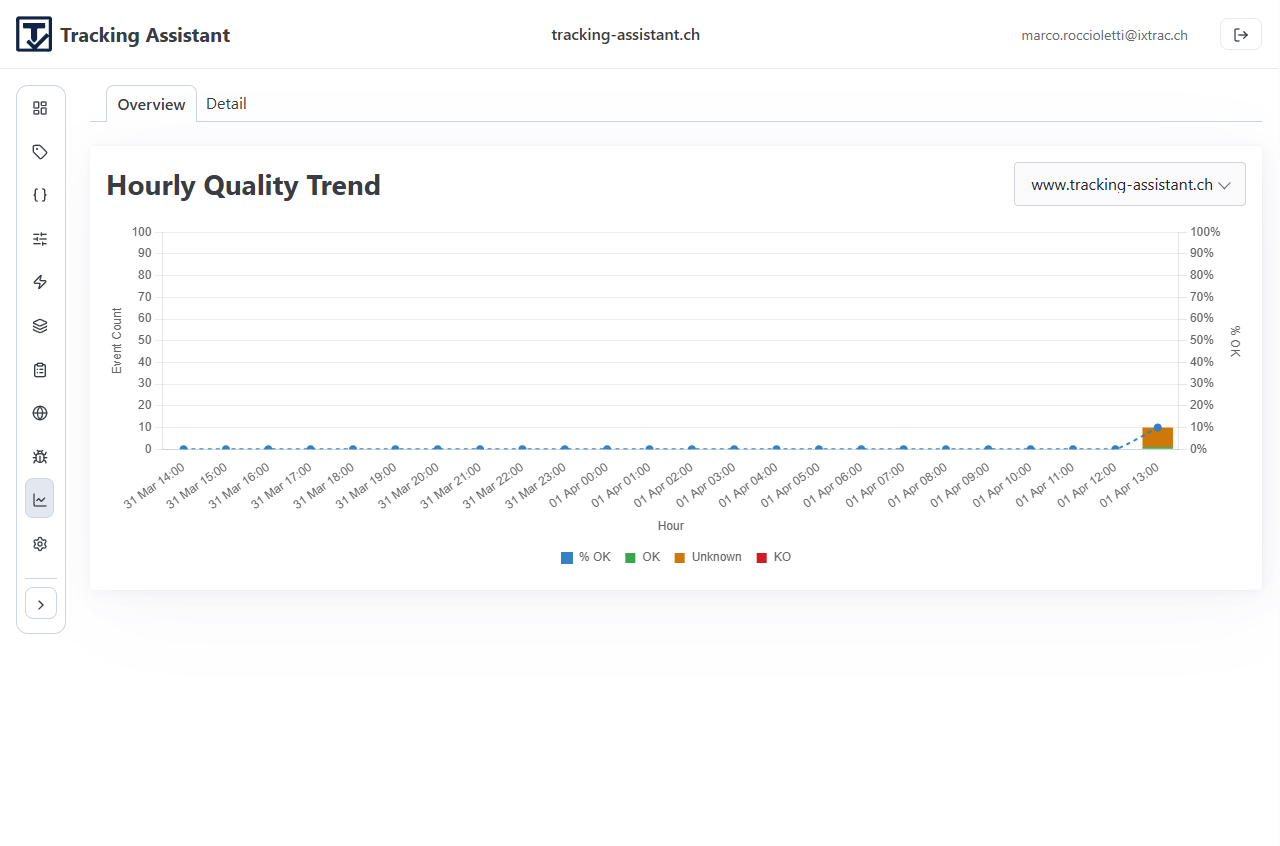
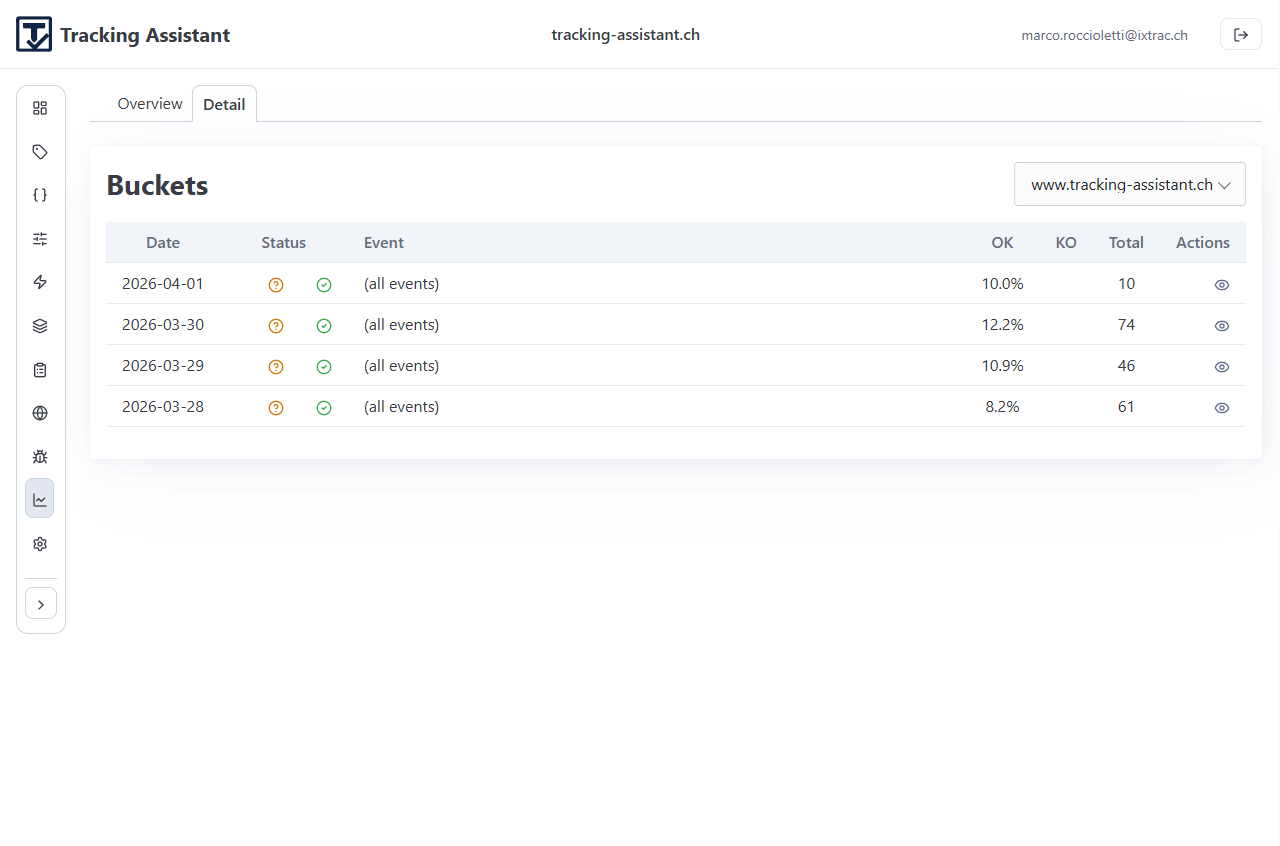
Use Monitoring for continuous runtime oversight after deployment.
Panels and purpose
- Overview: quality trend and daily bucket view.
- Detail: event-level drill-down for a selected day/asset.
- Bucket view: itemized records for investigation and follow-up actions.
Monitoring is where drift becomes visible over time. Unknown and error signals should feed back into specification and implementation updates.
Example screens
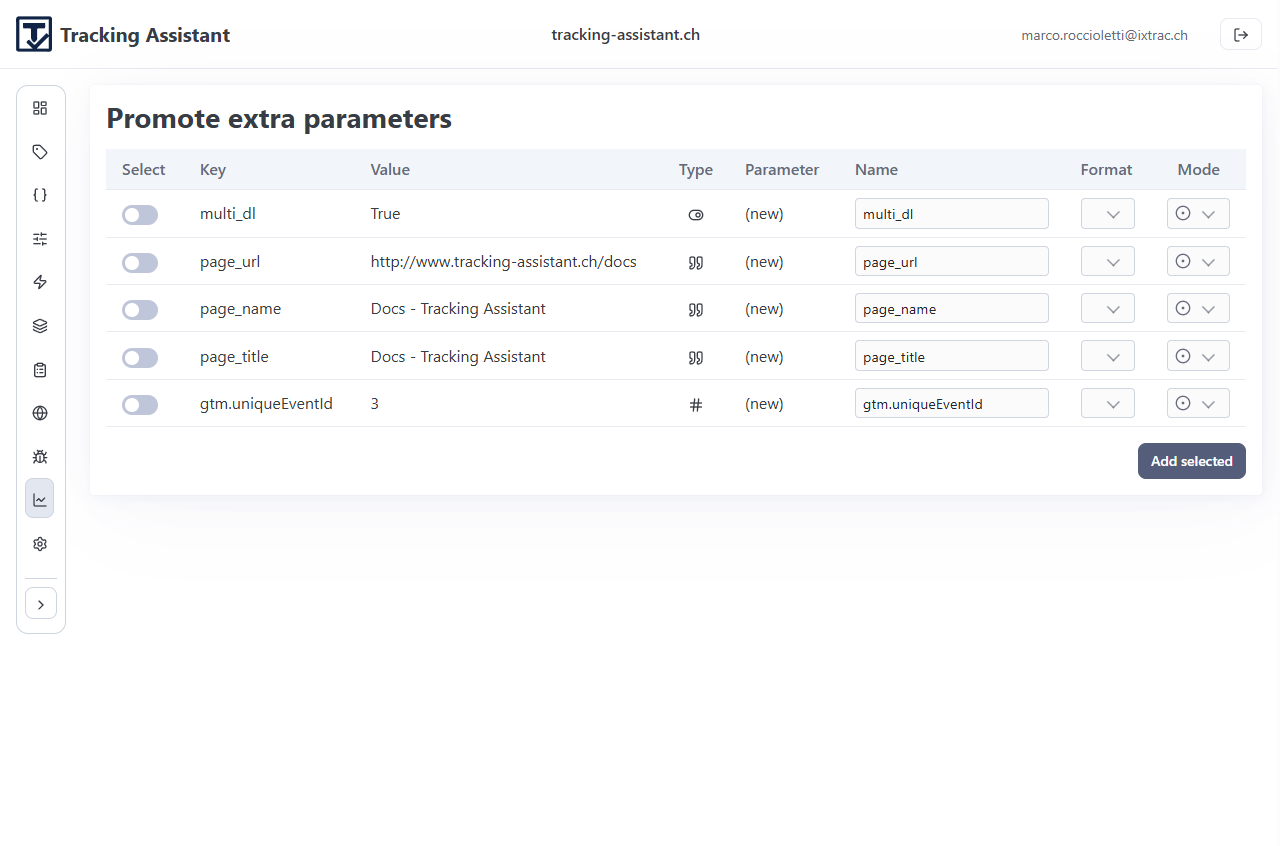
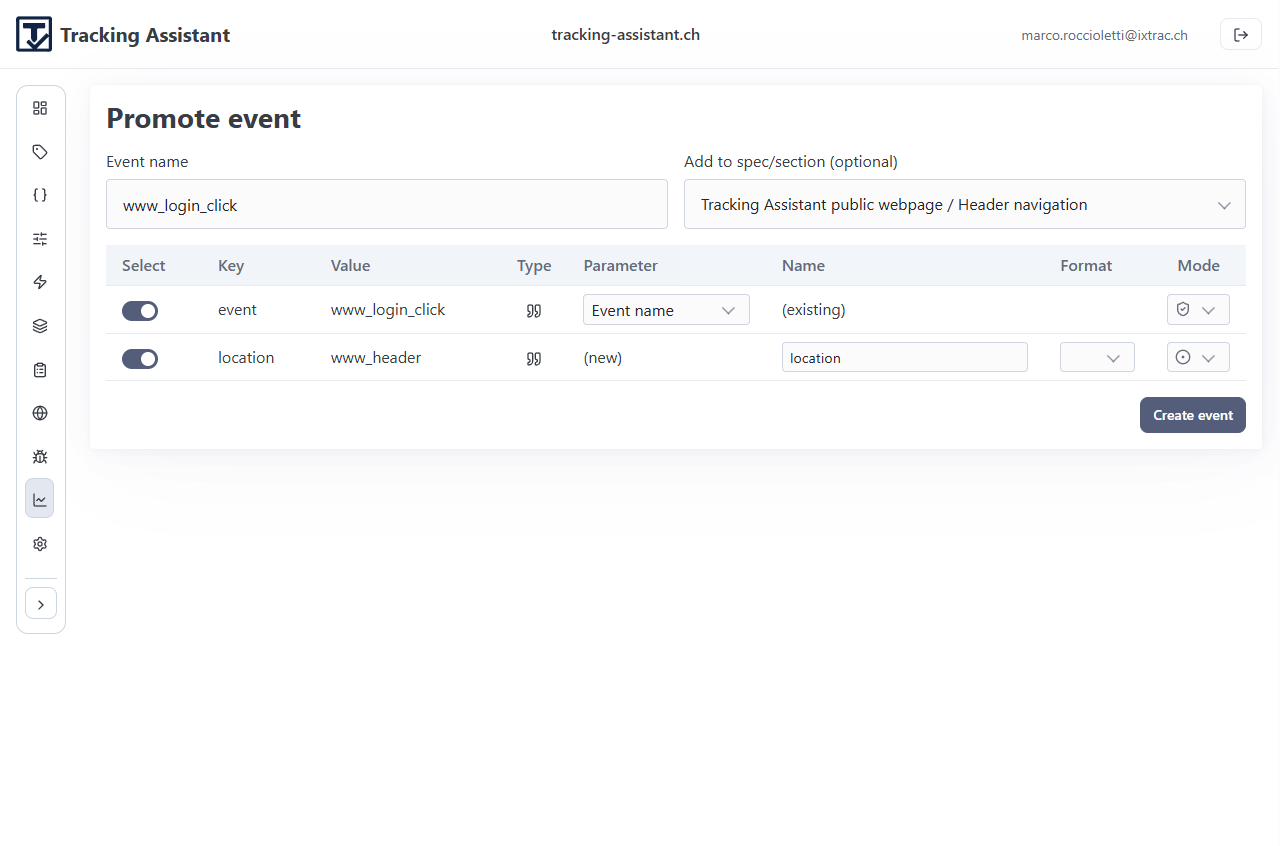
Promotion flows convert observed runtime deltas into controlled specification updates.
Supported promotion actions
- Promote extra parameters for known events.
- Promote completely new events discovered in traces or monitoring.
- Map promoted items to existing parameters where possible.
- Create new parameters with explicit kinds and formats when needed.
- Attach promoted events to chosen spec/section targets.
This closes the loop between observed behavior and governed definition while keeping change explicit.
Example screens
Protocols turn selected trace observations into structured, reviewable test artefacts.
Protocol workflow
- Create a protocol from selected trace items.
- Edit comments and expected values where needed.
- Insert additional expected events for full scenario coverage.
- Save and re-run when implementations change.
- Export protocol PDFs for audit and delivery records.
Treat protocols as living operational evidence tied to runtime behavior, not static documents.
A stable cadence keeps governance practical and lightweight.
Protocol workflow
- Weekly: review monitoring overview and top error/unknown buckets.
- Per release: run targeted traces on changed user flows.
- After incidents: promote validated deltas and version affected specs.
- Monthly: refresh protocol set for critical journeys.
Ownership works best when product, analytics, and engineering share the same workflow instead of splitting definition, validation, and reporting responsibilities.
Need help with your exact rollout path?
Share your current stack and we can map the first project setup and governance routine with you.